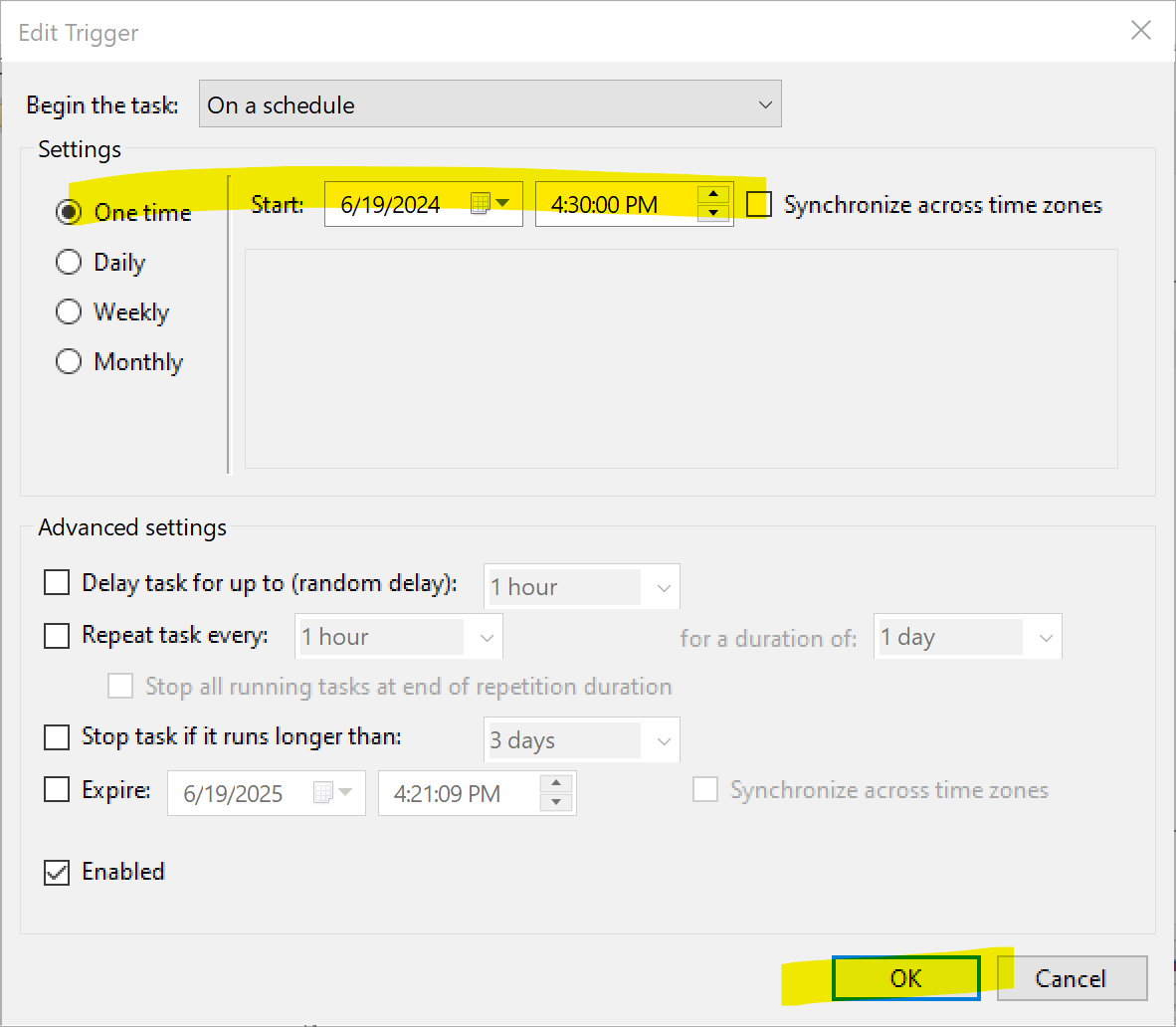
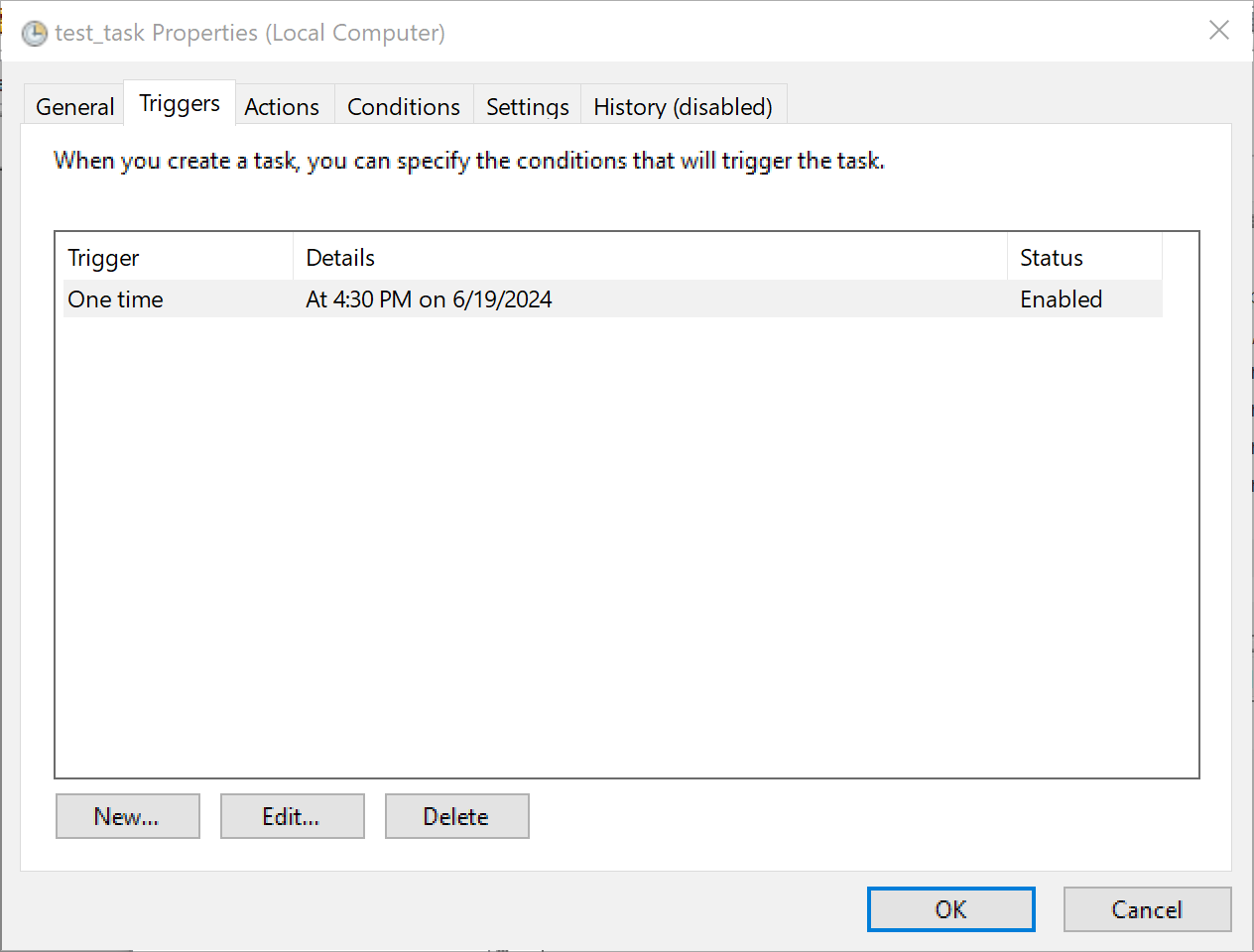
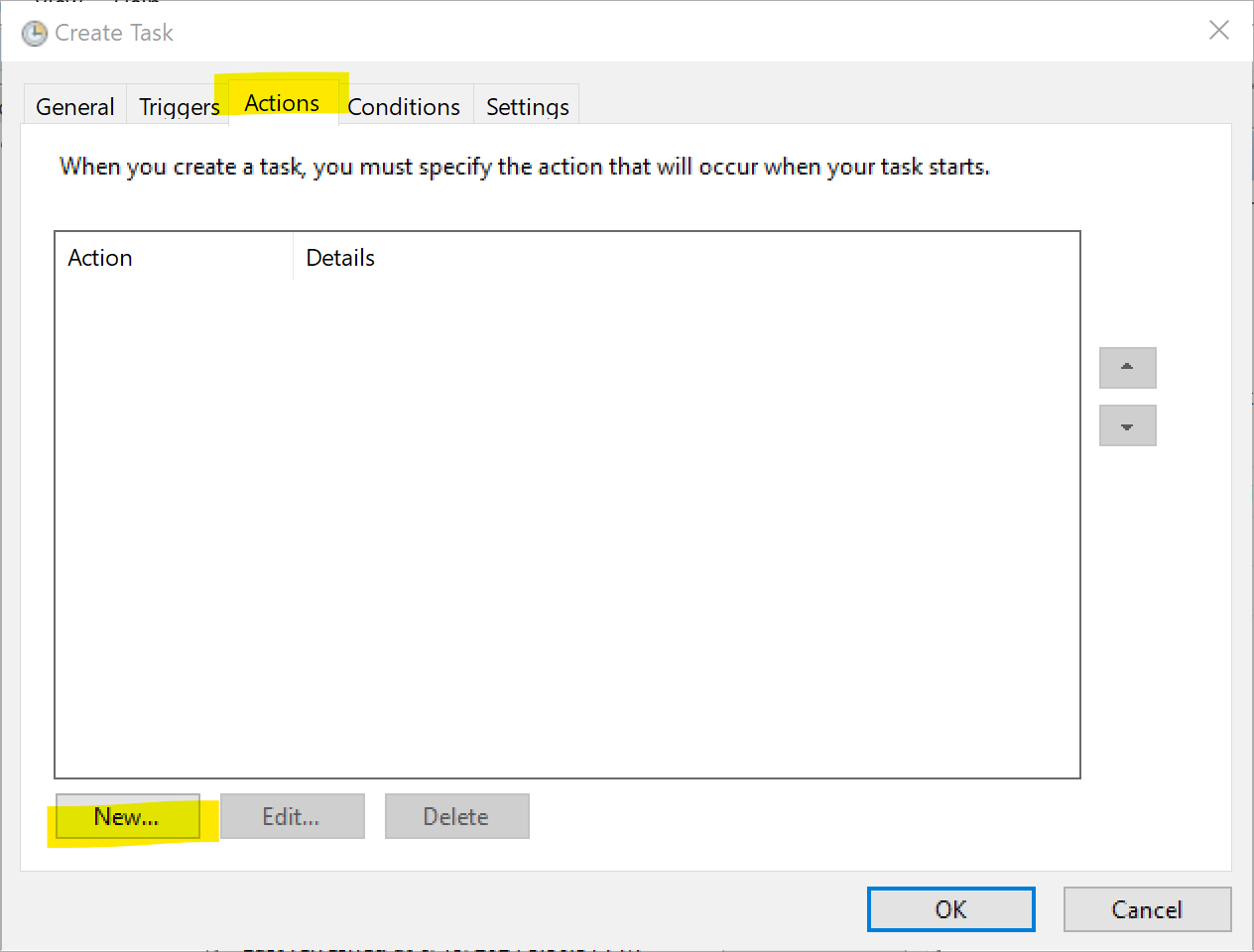
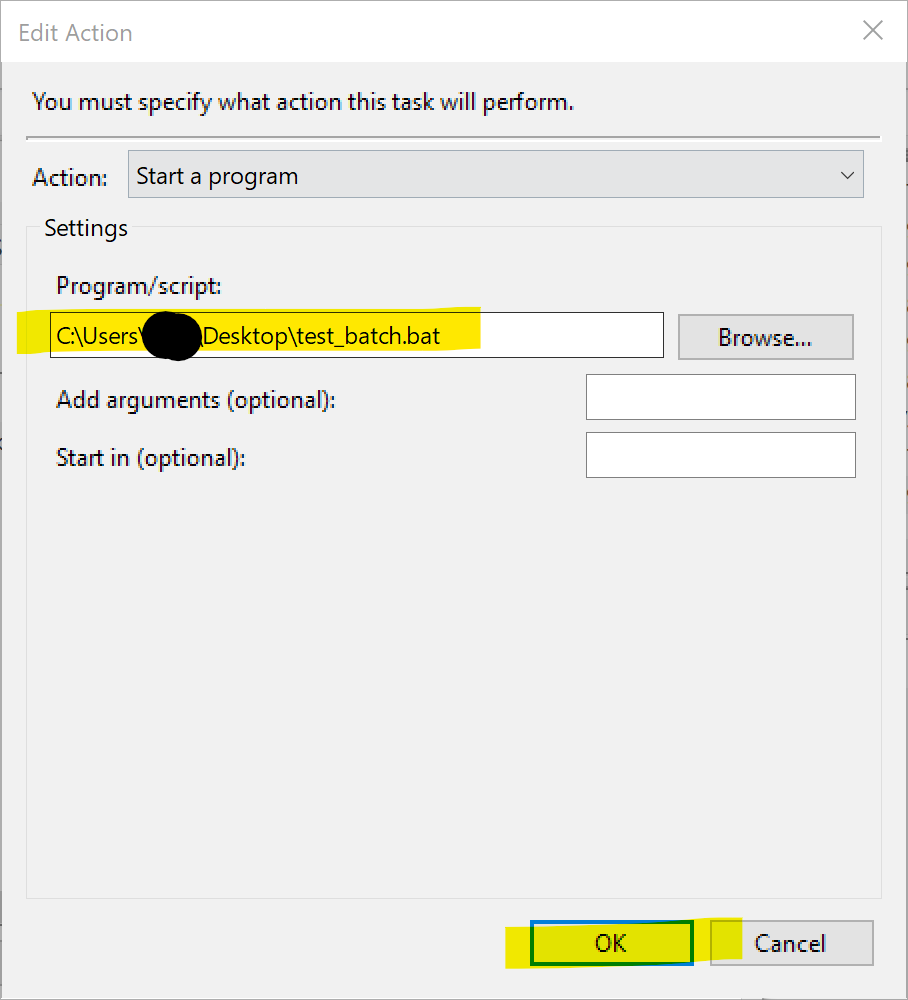
2011년에 "블랙스완"을 써서 유명해진 나심 탈렙이 2001년에 낸 책. 원제 Fooled by Randomness로 번역하면 '(우리는) 무작위성에 속고있는 중이다' 정도가 될 듯.
블랙스완의 내용과 겹치는 점이 많고, 좀 비슷한 스타일로 쓰여는데 블랙스완이 좀 더 재밌게 쓰여지긴 했다. 다방면으로 철학적 discussion을 하는 것은 블랙스완이 더 재미있고. 이 책은 살짝 약한 연습 version같은 느낌이 있다.
주 내용은, 성공이 행운에 의한 것인지 아닌지 잘 모르니까 한번 성공했다고 그 방법이 통할 것이라고 생각하지말라는 것이고. 무작위성(randomness)에 대한 연구자라고 본인은 주장하는 만큼, 무작위성에 대한 내용을 일반인도 좀 쉽게 이해하도록 좀 친절하게 설명해준 것 같다 (블랙스완에서는 어쩐지 덜 친절함).
블랙스완에서는 똑같은 randomness에 대한 얘기를 하고 똑같은 principle이지만, 대신 한번도 실패하지 않았다고 안실패한다고 생각하지말라, 큰 불행이 올 수도 있다는 식으로 얘기를 전개하였는데, 블랙스완의 방식이 사람들의 관심을 더 끌었다고 생각한다. 사람들은 부정적인 일이 더 관심이 많아서일까? 큰 행운이 생긴다는 얘기보다 큰 불행이 생긴다는 얘기에 더 많은 관심을 보이니까.
(블랙스완에서는 '블랙스완'이나 터키라는 눈에 보이는 것 같은 example과 Gaussian에 대한 좀 더 체계적인 비판, 그리고 다양한 철학적 stance를 보여주기위한 각종 캐릭터들, 그리고 자신의 memoir를 철학적 주장과 매우 교묘하고 신기하게 섞어놓은 뭐라 categorize하기 힘든, 이렇게 글을 풀어놓는 방식이 새롭다. 그리고 더 제멋대로라고 할까. Fooled By Randomness는 좀 더 대중적으로 읽히고 싶어서 쓴 책이고 블랙스완은 정말 더더 독자 눈치 안보고 쓰고 싶은데로 멋대로 자기 성향대로 최고로 잘난 척하면서 쓴 것 같은데도 더 재밌다)
블랙스완에서는 인간이 randomness를 인식하지 못하는 이유, 어떤 상황에서건 설명을 만들어내려고 하는 biological한 약점, 역사라는 것은 그때 그 순간에 일어난 일들을 순차적으로 기입하는 것이 아니라 그 한참 후의 '결과물'을 본 다음에만 이해할 수 있다는 새로운 관점, Gaussian을 좋아하는 또는 normal model을 좋아하는 사람들에 대한 끝없는 공격이 더 늘어났다. (그동안 behavioral economics가 발달하여 더 많은 사람들이 Taleb의 이야기를 들어주기 시작했는지도.. 아니면 그동안 더 명성을 쌓아서 하고 싶은 말을 할 수 있게 된 것인가.)